
1. NoSQL
1.1. Khái niệm
NoSQL là một khái niệm chỉ về một lớp các hệ cơ sở dữ liệu không sử dụng mô hình quan hệ. (RDBMS). RDBMS vốn tồn tại khá nhiều nhược điểm như có hiệu năng không tốt nếu kết nối dữ liệu nhiều bảng lại hay khi dữ liệu trong một bảng là rất lớn.
NoSQL ra đời năm 1998 bởi Carlo Strozzi khi ông lập mới một hệ cơ sở dữ liệu quan hệ mã nguồn mở nhanh và nhẹ không liên quan đến SQL Vào năm 2009, Eric Evans, nhân viên của Rackspace giới thiệu lại thuật ngữ NoSQL khi Johan Oskarsson của Last.fm muốn tổ chức một hội thảo về cơ sở dữ liệu nguồn mở phân tán. Thuật ngữ NoSQL đánh dấu bước phát triển của thế hệ CSDL mới: phân tán (distributed) + không ràng buộc (non-relational).
NoSQL được phát triển trên Javascript Framework với kiểu dữ liệu là JSON và dạng dữ liệu theo kiểu key và value (1 đặc trưng về dữ liệu trong JSON). NoSQL ra đời như là 1 mảnh vá cho những khuyết điểm và thiếu xót cũng như hạn chế của mô hình dữ liệu quan hệ RDBMS về tốc độ, tính năng, khả năng mở rộng, memory cache,...
NoSQL được sử dụng ở đâu? NoSQL được sử dụng ở rất nhiều công ty, tập đoàn lớn, ví dụ như FaceBook sử dụng Cassandra do FaceBook phát triển, Google phát triển và sử dụng BigTable,....,
- NoSQL lưu trữ dữ liệu của mình theo dạng cặp giá trị “key – value”. Sử dụng số lượng lớn các node để lưu trữ thông tin – Mô hình phân tán dưới sự kiểm soát phần mềm
- Chấp nhận dữ liệu bị trùng lặp do một số node sẽ lưu cùng thông tin giống nhau
- Một truy vấn sẽ được gửi tới nhiều máy cùng lúc, do đó khi một máy nào đó không phục vụ được sẽ không ảnh hưởng lắm đến chất lượng trả về kết quả
- Phi quan hệ – không có ràng buộc nào cho việc nhất quán dữ liệu
- Tính nhất quán không theo thời gian thực: Sau mỗi thay đổi CSDL, không cần tác động ngay đến tất cả các CSDL liên quan mà được lan truyền theo thời gian.
1.3. Các dạng NoSQL cơ bản
Key – value data stores: Dữ liệu lưu dưới dạng cặp key – value. Giá trị được truy xuất thông qua key.
- Ví dụ : Redis, Dynomite, Project Voldemort.
- Thường cho: Content caching Applications
- Ưu điểm: Tìm kiếm rất nhanh
- Nhược điểm: Lưu dữ liệu không theo khuôn dạng (schema) nhất định
Column-based – Tabular: Cơ sở dữ liệu tổ chức dưới dạng các bảng. Gần giống với mô hình RDBMS. Tuy nhiên, Chúng lưu dữ liệu bởi các cột chứ không phải bằng các dòng. Nó khá thích hợp với để hiển thị bằng các phần mềm quản lý kho dữ liệu
- Ví dụ : Apache Hbase, Apache Cassandra, Hypertable
- Thường cho: các hệ phân tán file
- Ưu điểm: Tìm kiếm nhanh, Phân tán dữ liệu tốt
- Nhược điểm: Hỗ trợ được với rất ít phần mềm
Document-based: Dữ liệu (bán cấu trúc hay semi-structured) được lưu trữ và tổ chức dưới dạng một tập hợp các document. Các document này linh hoạt, mỗi document có một tập nhiều trường.
- Ví dụ : Apache CouchDB và MongoDB
- Thường cho: Web applications
- Ưu điểm: Dùng khi dữ liệu nguồn không được mô tả đầy đủ
- Nhược điểm: Hiệu năng truy vấn, Không có cú pháp chuẩn cho câu truy vấn dữ liệu
Graph-based data-stores: Những CSDL này áp dụng lý thuyết đồ thị trong khoa học máy tính để lưu trữ và truy xuất dữ liệu. Chúng tập trung vào tính rời rạc giữa các phần dữ liệu. Các phần tử đơn vị dữ liệu được biểu thị như một nút và liên kết với các thành phần khác bằng các cạnh.
- Ví dụ : Neo4j, InfiniteGraph, DEX
- Thường cho: Social networking, Hệ trợ giúp
- Ưu điểm: Ứng dụng các thuật toán trên đồ thị như Đường đi ngắn nhất, liên thông,…
- Nhược điểm: Phải duyệt nội bộ đồ thị, để trả lời lại các truy vấn. Không dễ để phân tán
2. Mongo DB
2.1. Khái quát
MongoDB (bắt nguồn từ “humongous”) là một hệ cơ sở dữ liệu NoSQL mã nguồn mở. 
Hình 2 – Logo của MongoDB
Thay cho việc lưu trữ dữ liệu vào các bảng có quan hệ với nhau như truyền thống, MongoDB lưu các dữ liệu cấu trúc dưới dạng giống với JSON(JavaScript Object Notation) và gọi tên là BSON. Dự án được bắt đầu triển khai vào tháng 10 năm 2007 bởi 10gen trong khi công ty này đang xây dựng một nền tảng như là dịch vụ (Platform as a Service) giống như Google App Engine. Phải đến năm 2009, dự án này được tách độc lập. Hệ thống có thể chạy trên Windows, Linux, OS X và Solaris. Nó được một số tổ chức sử dụng trong thực tế như:
- Caigslist : Công ty làm việc trong lịch vực môi giới quảng cáo trên các website khác (giống adMicro của Việt Nam). MongoDB giúp cho công ty này quản lý hàng tỉ các bản ghi quảng cáo thuận tiện và nhanh chóng.
- Foursquare là một mạng xã hội gắn các thông tin địa lý. Công ty này cần lưu dữ liệu của rất rất nhiều vị trí của các địa điểm như quán cafe, nhà hàng, điểm giải trí, lịch sử, … và ghi lại những nơi mà người sử dụng đã đi qua.
- CERN : Trung tâm nghiên cứu năng lượng nguyên tử của Châu Âu, sử dụng MongoDB để lưu trữ lại các kết quả, dữ liệu thí nghiệm của mình. Đây là một lượng dữ liệu khổng lồ sẽ dùng để sử dụng trong tương lai.
- MTV Networks, Disney Interactive Media Group, bit.ly, The New York Times, The Guardian, SourceForge, Barclays, …
2.2. Tại sao lại chọn MongoDB?
MongoDB có những ưu điểm sau đây
- Dễ học, có một số nét khá giống với CSDL quan hệ – Quản lý bằng command line hoặc bằng GUI như RockMongo hoặc phpMoAdmin
- Linh động, không cần phải định nghĩa cấu trúc dữ liệu trước khi tiến hành lưu trữ nó -> rất tốt khi ta cần làm việc với các dạng dữ liệu không có cấu trúc.
- Khả năng mở rộng tốt (distributed horizontally), khả năng cân bằng tải cao, tích hợp các công nghệ quản lý dữ liệu vẫn tốt khi kích thước và thông lượng trao đổi dữ liệu tăng.
- Miễn phí
2.3. Kiến trúc tổng quát
Một MongoDB Server sẽ chứa nhiều database. Mỗi database lại chứa một hoặc nhiều colection. Đây là một tập các documnents, về mặt logic thì chúng gần tương tự như các table trong CSDL quan hệ. Tuy nhiên, điểm hay ở đây là ta không cần phải định nghĩa trước cấu trúc của dữ liệu trước khi thao tác thêm, sửa dữ liệu… Một document là một đơn vị dữ liệu – một bản ghi (không lớn hơn 16MB). Mỗi chúng lại chứa một tập các trước hoặc các cặp key – value. Key là một chuỗi ký tự, dùng để truy xuất giá trị dạng : string, integer, double, … Dưới đây là một ví dụ về MongoDB document
{
_id : ObjectId("4db31fa0ba3aba54146d851a"),
username : "joegunchy",
email : "joe@mysite.org",
age : 26,
is_admin : true,
created : "Sun Apr 24 2011 01:52:58 GMT+0700 (BDST)"
}
Cấu trúc có vẻ khá giống JSON, tuy nhiên, khi lưu trữ document này ra database, MongoDB sẽ serialize dữ liệu thành một dạng mã hóa nhị phân đặc biệt – BSON. Ưu điểm của BSON là hiệu quả hơn các dạng format trung gian như XML hay JSON cả hệ tiêu thụ bộ nhớ lẫn hiệu năng xử lý. BSON hỗ trợ toàn bộ dạng dữ liệu mà JSON hỗ trợ (string, integer, double, Boolean, array, object, null) và thêm một số dạng dữ liệu đặc biệt như regular expression, object ID, date, binary, code. 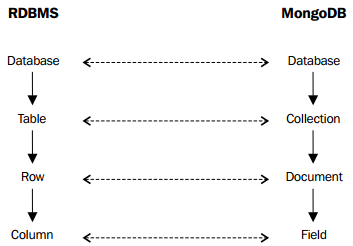

Hình 3 – So sánh giữa RDBMS và MongoDB

Hình 4 – So sánh Table với Collection
2.4. Cơ chế hoạt động chi tiết của MongoDB
2.4.1. Sharding
Sharding là gì?

Sharding là cơ chế tự động của MongoDB dùng để chia tách một dữ liệu kích thước lớn cho rất nhiều server (thường gọi là cluster). Sharding được thiết kế để phục vụ 3 mục điêu cơ bản sau
- Làm cho cluster “trong suốt” với người dùng: Để hoàn thành nhiệm vụ này, MongoDB sử dụng một quá trình routing đặc biết gọi là mongos. Mongos đứng trước cluster, đóng vai trò điều phối việc truy cập đến shard nào, trả dữ liệu từ shard nào ra. Nó chuyển tiếp các request tới các server khác có tài nguyên hoặc đến cluster đằng sau nó. Sau đó lắp ráp lại, và gửi các response lại về cho các client. Do đó, các client không cần biết rằng chúng đang giao tiếp với cluster nào thật sự mà chỉ biết rằng mình đang kết nối tới một server bình thường. Đây gọi là tính “trong suốt” với người sử dụng

Hình 5 – Mongos
- Làm cho cluster luôn sẵn sàng để đọc hoặc ghi: Một cluster còn tồn tại phải đảm bảo được rằng nó luôn sẵn sàng. Mỗi phần con trong cluster sẽ có ít nhất một vài tiến trình phục vụ dự bị trên máy khác.
- Làm cho cluster phát triển “tự nhiên”: Bất cứ khi nào người dùng cần thêm dung lượng, họ có thể thêm một cách dễ dàng Mỗi cluster khi được quản lý lại “thể hiện” như một node riêng lẻ và dễ dàng config.
2.4.2. Cơ chế hoạt động của Sharding
Một shard là một hoặc nhiều server trong một cluster chịu trách nhiệm với một tập các dữ liệu lưu trữ. Ví dụ, nếu ta có một cluster chứa 1.000.000 documents – 1.000.000 tài khoản website, thì một shard chứa khoảng 200.000 tài khoản. Nếu shard có chứa nhiều hơn một server, thì mỗi server đó sẽ lưu một bản copy giống hệt nhau của một tập con dữ liệu. Điều này có nghĩa là một shard cũng là một bộ các bản sao dữ liệu 

Hình 6 – Các bản sao dữ liệu trong một shard
Để đồng đều phân phối dữ liệu vào các shard, MongoDB lại di chuyển một tập con dữ liệu từ shard này sang shard khác. Việc chọn lựa tập con nào để chuyển đi lại phụ thuộc vào khóa mà ta chọn. Ví dụ, chúng ta sẽ chọn cách thức chia một collection của các user dựa vào trường username và sử dụng khoảng chia giống trong Toán học ‘[‘ , ‘]’ , ‘(‘ , ‘)’.
2.1.1.2.2. Cơ chế phân tán dữ liệu
2.1.1.2.2.1. Một khoảng cho một shard
Đây là cách đơn giản nhất để phân tán dữ liệu ra cho các shard. Mỗi shard sẽ đảm nhận một tập con dữ liệu. Giả sử có 4 shard và 4 khoảng chia dữ liệu, ta sẽ chia như sau: 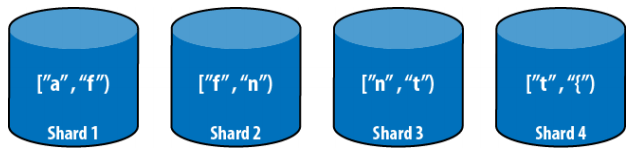

Hình 7 – 4 khoảng cho 4 shard [a,f), [f,n), [n,t), [t,{)
Chia như thế này là rất dễ hiểu nhưng nó trở nên rất phức tạp cho các hệ thống lớn. Giả sử rằng có một lượng lớn đăng ký username có chữ cái bắt đầu thuộc [a,f), điều này làm cho shard 1 trở nên lớn, giải quyết đơn giản bằng cách điều chỉnh cho shard 1 chỉ lấy từ [a,c) và shard 2 lấy nhiều hơn, từ [c,n) 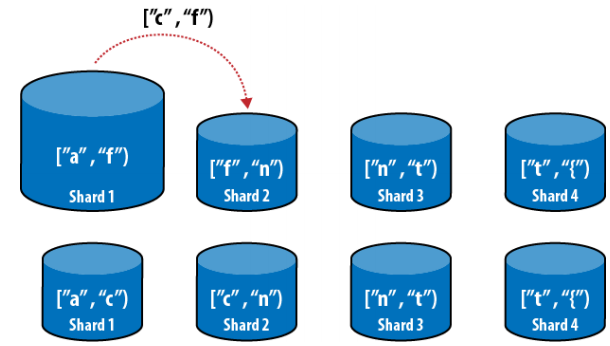

Hình 8 – Giới hạn lại khoảng cho shard 1 sang shard 2
Mọi thứ có vẻ ok, nhưng nếu shard 2 trở nên overload thì lại giải quyết thế nào? Giả sử rằng shard 1 và shard 2 chứa 500GB dữ liệu, shard 3 và shard 4 mỗi cái chứa 300GB dữ liệu. Giải quyết vấn đề này như sau: 

Hình 9 – Chuyển dữ liệu sang shard tiếp theo
- Chuyển 100GB từ shard 1 sang shard 2
- Chuyển 200GB từ shard 2 sang shard 3
- Chuyển 100GB từ shard 3 sáng shard 4
Mỗi shard đều chứa 400GB dữ liệu, có vẻ ổn. Tổng cộng, đã chuyển 400GB dữ liệu qua mạng, quá lớn!!! Cách khác, thêm mới một shard thì sao? Giả sử có 4 shard, mỗi shard hiện đang có 500GB dữ liệu, thêm vào shard 5 và chia dữ liệu. 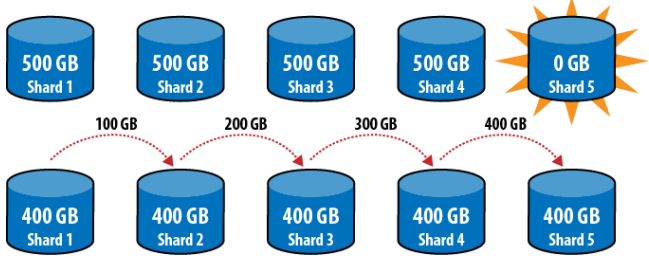

Hình 10 – Thêm mới shard rồi chia đều dữ liệu
- Chuyển 400GB từ shard 4 sang shard 5
- Chuyển 300GB từ shard 3 sang shard 4
- Chuyển 200GB từ shard 2 sang shard 3
- Chuyển 100GB từ shard 1 sang shard 2
Mỗi shard đều chứa 400GB dữ liệu, vẫn ổn. Tổng cộng, đã chuyển 1TB dữ liệu qua mạng, quá lớn!!! Rõ ràng là cách thức chia mỗi khoảng trên một shard này làm cho vấn đề trao đổi dữ liệu, xử lý trong hệ thống lớn trở nên quá đắt đỏ và tốn kém. Do đó, MongoDB không phân tán dữ liệu theo cách thô thiển như thế này, thay vào đó là nhiều khoảng trên nhiều shard.
2.1.1.2.2.2. Nhiều khoảng trên nhiều shard
Giả sử tình huống cần giải quyết giống với hình 8, shard 1 và shard 2, mỗi shard có 500GB dữ liệu còn shard 3 và shard 4 mỗi shard có 300GB dữ liệu. Lúc này, ta sẽ cho phép mỗi shard chứa nhiều phần của khoảng chia. Chia dữ liệu trong shard 1 thành hai khoảng :
- 400GB cho [a,d)
- 100GB cho [d,f)
Chia dữ liệu trong shard 2 thành hai khoảng :
- 400GB cho [f,j)
- 100GB cho [j,n)
Lúc này, ta di chuyển:
- 100GB [d,f) từ shard 1 sang shard 4
- 100GB [j,n) từ shard 2 sang shard 3
Vậy, kết luận cả 4 shard đều chứa 400GB dữ liệu và chỉ phải trao đổi qua mạng 200GB dữ liệu. Điều này chấp nhận được 

Hình 11 – Cho phép đa, không liên tiếp các khoảng cho phép ta lấy ra và di chuyển dữ liệu đi bất cứ đâu
Với ví dụ của hình 9, nếu ta thêm vào một shard mới, ta chỉ lấy đi 100GB dữ liệu trên mỗi 4 shard cũ để cho vào shard 5 mới, lúc này các shard đã lưu dữ liệu như nhau và thông lượng trao đổi dữ liệu qua mạng ở mức tốt nhất 400GB 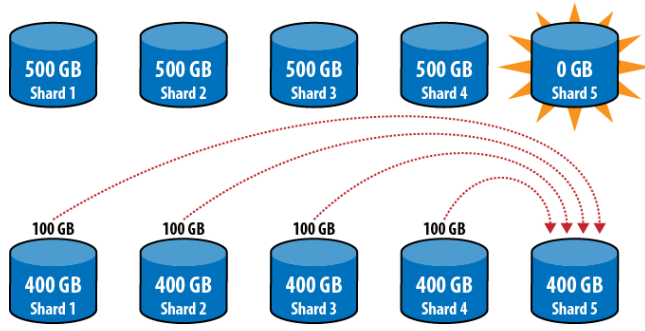

Hình 12 – Hớt 100GB của mỗi shard ném vào shard 5
Đây là cách mà MongoDB phân tán dữ liệu giữa các shard với nhau, nếu có shard nào mất cân bằng, dữ liệu sẽ được điều chỉnh để phục hồi lại trạng thái cân bằng mới giữa các shard.
2.1.1.2.3. Cơ chế tách, tạo đoạn của Sharding
Khi ta quyết định phân tán dữ liệu, ta phải chọn ra một khóa được sử dụng để tách các khoảng với nhau (ở trên ta chọn username). Khóa này được gọi là shard key có thể là bất kỳ hoặc tập bất kỳ trường nào. Giả sử rằng collection của chúng ta có các document như sau (không kể ra_ids):  Nếu ta chọn Age là shard key và khoảng là [15,26) -> Kết quả là
Nếu ta chọn Age là shard key và khoảng là [15,26) -> Kết quả là 
 Nếu ta chọn Age là shard key và khoảng là [15,26) -> Kết quả là
Nếu ta chọn Age là shard key và khoảng là [15,26) -> Kết quả là 
2.1.1.2.3. Cơ chế Sharding các Collection
Lần đầu tiên khi shard một Collection – bảng, MongoDB chỉ tảo ra một chunk cho bảng này sẵn sàng cho việc thêm mới dữ liệu. Chunk này sẽ có khoảng là (-∞,∞), với giá trị -∞ tương đương bởi $minKey và ∞ tương đương với $maxKey. Dĩ nhiên nếu dữ liệu trong bảng là đủ lớn, MongoDB sẽ tự động chia thành nhiều chunk hơn để lưu dữ liệu. Khi dữ liệu lớn dần, MongoDB tự động tách chunk như sau: chia đôi khoảng hiện tại ra theo khoảng của dữ liệu chọn làm key. Ví dụ trên, giả sử nó chọn chia đôi thành
- Một chunk chứa tuổi nhỏ hơn 15 (-∞,15)
- Một chunk chứa tuổi lớn hơn hoặc bằng 15 [15, ∞)
Nếu tiếp tục có nhiều dữ liệu được thêm vào chunk [15, ∞), nó sẽ bị chia tiếp, chẳng hạn [15, 26) và [26, ∞). Hiện tại ta có 3 chunk: (-∞,15), [15, 26) và [26, ∞) và cứ như vậy. Yêu cầu đặt ra:
- Việc chia chunk phải liên tiếp
- Một chunk chỉ tương đương với một khoảng và ngược lại
- Mỗi một document chỉ thuộc một và chỉ một chunk

Hình 13 – Chia một chunk ra thành hai
Một số chú ý
- Việc chia chunk này phụ thuộc tất cả vào shard key do vậy MongoDB không cho phép ta thêm dữ liệu mà rỗng hoặc không có shard key (ít nhất phải để null). Ta cũng không thể đổi được giá trị trường shard key, muốn vậy, bắt buộc phải thay đổi từ phía client, sau đó xóa, và thêm lại document muốn đổi shard key.
- Nếu ta thêm nhiều kiểu dữ liệu vào nội dung trường age ở trên, ví dụ như một mảng, boolean, số, string, null, … MongoDB vẫn chấp nhận và dùng quy tắc chia chunk cho sharding theo thứ tự sau:
null < numbers < strings < objects < arrays < binary data < ObjectIds < booleans < dates < regular expressions
- Ở các hệ thống thực tế một chunk thường chỉ được 200MB dữ liệu (còn mặc định là 64 MB) Một chunk là đơn vị logic. Các document trong một chunk cũng không nhất thiết phải nối tiếp nhau trong đĩa cứng vật lý. Chúng vẫn rải rác ngẫu nhiên trong collection. Tuy chỉ có một document thuộc về chunk thứ i, nếu và chỉ nếu shard key của nó thuộc khoảng chia của chunk thứ i.
2.4.3 Balancing – Cân bằng tải
Nếu có nhiều shard đang sẵn sàng và có thêm chứa thêm dữ liệu, MongoDB sẽ tiến hành chuyển dữ liệu từ các shard khác sang để cân bằng tải. Cách thức tiến hành là di chuyển các chunk từ shard này sang shard khác một cách tự động. Balancing cũng có thể bị tắt hoặc bật nếu admin muốn Balancing cũng không được đảm bảo ngay tức thì, chúng ta hãy xem ví dụ dưới đây 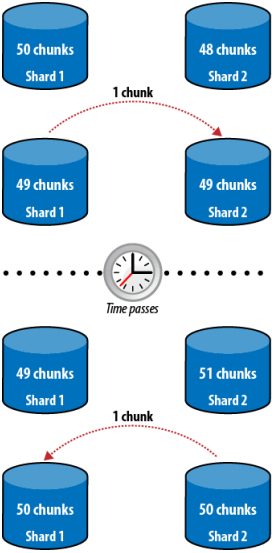

Hình 14 – Nếu cần bằng real time, sẽ có những tài nguyên bị di chuyển lãng phí
2.4.4 Cấu hình cho một Cluster
Chọn Shard Key
a. Low-Cardinality Shard Key
Đây là việc chọn khóa một cách trực quan như ví dụ “Tôi đang có 4 Shard, Tôi chọn một trường nào đó làm Shard key để sao cho chia được ok trường đó thành 4 khoảng”. Cụ thể hơn, ta có 7 khoảng chia vào 7 shard như sau:
- (-∞, “Antarctica”)
- [“Antarctica”, “Asia”)
- [“Asia”, “Australia”)
- [“Australia”, “Europe”)
- [“Europe”, “North America”)
- [“North America”, “South America”)
- [“South America”, ∞)

Hình 15 – Một Shard cho một Châu lục
Điều này mới đầu rất ổn. Nhưng để ý, nếu về lâu dài, dữ liệu trong châu Á chẳng hạn tự nhiên lên cao hơn các châu khác thì ta không biết sẽ phân chia lại khoảng các shard như thế nào để cân bằng vì đã chọn một shard – một châu lục rồi. Cách giải quyết tình thế là ở đây lấy thêm một trường nữa làm Shard Key. Shard key có hai trường sẽ cho phép chia thành nhiều khoảng hơn. Nhưng kết lại, đây nói chung không phải là cách chọn Shard Key tốt.
b. Ascending Shard Key
Như chúng ta đã biết, đọc dữ liệu từ RAM nhanh hơn nhiều so với đọc dữ liệu từ thiết bị lưu trữ ngoại vi. Theo nghiên cứu cho thấy, ở hầu hết các phần mềm hiện nay, ta thường làm việc với dữ liệu gần đây hơn là những dữ liệu lâu cũ; vì vậy, ta muốn dùng một shard key nào đó mà phân chia được dữ liệu gần đây để tiện việc đọc ra. Đa phần mọi người sẽ nghĩ ngay đến việc dùng tem thời gian (timestamp) hay trường ObjectId nhưng điều này không mang lại kết quả như mong đợi, ta cùng xem ví dụ sau: Giả sử ta đang quản lý dịch vụ like của facebook, mỗi document sẽ lưu hai trường
- Ai là người gửi
- Khi nào nó được gửi
Vấn đề như sau: Bắt đầu bằng một shard (-∞, ∞) – và dùng shard key là timestamp, dữ liệu thêm mới sẽ vào shard này và đến một lúc nào đó dữ liệu tăng lên sẽ chia thành hai shard (-∞, 1000) và [1000, ∞). Dữ liệu thêm mới sẽ nhảy vào shard [1000, ∞). Đến một lúc nào đó, shard này lại chia thành hai [1000, 3000) và [3000, ∞). Dữ liệu thêm mới lại chỉ vào shard [3000, ∞) . . . Tuy có ưu điểm là khi làm việc, ta thường làm việc với shard cuối cùng – chứa nhiều dữ liệu gần đây nhưng nhược điểm lại lấn át bởi vì dữ liệu thêm mới chỉ thêm vào shard cuối cùng và quan trọng là shard đó luôn luôn phải chia ra. Điều này sinh ra các dòng dữ liệu chuyển qua lại lãng phí giữa các shard.
c. Random Shard Key
Để tránh nhược điểm trên, ta lại chọn cách thức chọn shard key mới: ngấu nhiên. Mới đầu làm việc tốt nhưng dữ liệu tăng lên, hệ thống hoạt động càng ngày càng chậm đi. Giả sử ta muốn lưu ảnh của một website vào CSDL, Mỗi document gồm có:
- Định dạng nhị phân của ảnh
- Hash MD5 của ảnh
- Một chú thích ảnh
- Ngày lưu bức ảnh được chụp
- Ai chụp nó
Tiến hành chọn trường Hash MD5 để làm shard key. Càng ngày, dữ liệu lớn dần lên và chúng ta có một loạt các chunk phân bố đồng đều trên các shard. Giả sử rằng, Shard 2 đang có nhiều hơn Shard 1 10 chunk và phải cân bằng. MongoDB lúc này sẽ load ngẫu nhiên 5 chunk để chuyển. Do chúng phân bố ngẫu nhiên nên việc lấy dữ liệu này không thông qua đánh index. Một lượng lớn công sức sẽ phải bỏ ra để chuyển dữ liệu (qua RAM, qua IO,…). Chính vì để ngẫu nhiên, không đánh index nên việc truy vấn dữ liệu diễn ra chậm
d. Good Shard Key
Rút cuộc, câu chuyện của ta là phải chọn một shard key sao cho nó đảm bảo tính chia nhỏ được của khoảng dữ liệu nhưng không nhỏ tới mức biến nó thành nhược điểm. Kết hợp ascending key + search key Đa phần chúng ta chỉ làm việc với các dữ liệu gần đây, nên việc chia khoảng bằng date/time là hợp lý và phân bố khá đều. Chúng ta áp dụng điều này bằng cách sử dụng cặp shard key – một loại key khác (như ascending key dạng thô, search key) Giả sử rằng ta đang có một phần mềm phân tích và cần dữ liệu của tháng gần đây nhất. Ta shard trên 2 trương {month, user}.
- Khởi đầu có 2 chunk ((-∞,-∞), (∞,∞)).
- Khi dữ liệu nhiều lên, chia chunk thành hai ví dụ như ((-∞, -∞),(“2011-04”, “susan”))and [(“2011-04”, “susan”), (∞, ∞))
- Tiếp tục, dữ liệu tăng lên, các chunk tiếp theo được sinh ra trong 04 – 2011 sẽ được chuyển sang shard khác, MongoDB sẽ dần dần cân bằng tải các cluster. Sang tháng 5, ta tạo ra một chunk mới – khoảng 05 – 2011. Đến tháng 06 – 2011, ta không cần đến dữ liệu của tháng 04 nữa, dữ liệu này có thể cất đi. Nhưng khi muốn xem lại lịch sử hoạt động, chúng ta không cần chia hoặc di chuyển bất kể dữ liệu gì hết (điểm yếu của random shard key)
3. Demo
Ta sẽ thử nghiệm về việc tự động chia chunk giữa các shard như sau:
Bước chuẩn bị :
Ở máy chủ: tạo thư mục /data/db và /data/configdb Ở máy con(chứa các shard con): tạo thư mục /data/db
a. Máy chủ: Khởi động mongoDB Server ở máy chủ chế độ chờ config với lệnh
mongod –configsvr
b. Máy chủ: Thiết lập config cho máy chủ mongos để chia các chunk (192.168.1.2 đang là ip của máy chủ) Ta thiết lập –chunkSize 1 (chunk chỉ lớn 1MB) để thấy việc chuyển chunk cho nhanh (nếu không có, mặc định là 64MB) với lệnh
mongos –configdb 192.168.1.2 [–chunkSize 1]
c. Các máy con: Khởi tạo các shard ở máy con
mongod –shardsvr
d. Máy chủ chạy
mongo localhost:27017/admin
> db.runCommand({addshard:”192.168.x.x:27018″})
> db.runCommand({enablesharding:”test”})
> db.runCommand({shardcollection: “test.table1″, key: {_id: 1}});
Máy chủ lần lượt add các shard vừa tạo (cổng mặc định của shard là 27018). Áp dụng sharding trên db “test”, collection “table1”, key trên trường “_id” (_id: 1 – 1 nghĩa là on – chọn trường này làm shard key) (có thể chọn nhiều trường cùng làm shard key như đã trình bày ở trên)





it's a good article for me :))
ReplyDelete2.4.3 cấu hình cho một cluster
ReplyDelete2.4.3.1. Chọn Shard Key
thế còn 2.3.4.2? 2.4.3.3? ... đâu rồi hả ad? đang đọc hay mà? :(